全球有7000多种语言,但其中4000多种仅能书写,无法进行听说交流,像谷歌翻译这样的自动翻译软件也仅能翻译100种语言,目前,科学家最新研究称,未来我们能使用自动翻译软件实现更多语言的交流沟通。
设想一下,当你收到一条可能包含救命的信息,但你一个字也看不懂,你甚至不确定这条信息是用哪种语言书写的,此时你怎么办?
如果该条信息是法语或者西班牙语,把它输入到自动翻译软件中会就立即解开谜团,并给出一个准确的英语版翻译答案,然而,全球许多语言仍无法进行机器翻译,包括数百万人使用的语言,例如:非洲的沃洛夫语、卢干达语、契维语和埃维语。这是因为支持这些翻译软件的算法是基于人类翻译文本,理想情况下,该语言的翻译文本需要达到数百万字。

联合国每年产生大量翻译文本,可用于训练翻译算法
由于加拿大议会、联合国和欧盟等多语言机构的存在,英语、法语、西班牙语和德语等语言有大量的翻译素材,不同国家的译员人工翻译大量笔录和其他文件,仅欧洲议会在过去10年里,在23种语言中产生了13.7亿个单词的翻译数据。
然而,对于那些使用广泛但翻译内容不丰富的语言,就不存在这样的数据信息库,它们也被称为低资源语言。这些语言的备用机器翻译培训素材包括宗教出版物,例如:翻译数次的《圣经》,但这是匮乏的翻译数据,并不能设计准确、广泛应用的自动翻译软件。
目前,谷歌翻译软件提供了大约108种不同语言的交互翻译功能,而微软“必应翻译”提供了大约70种语言,然而,世界上有7000多种口语,其中至少4000种拥有文字系统。
这种语言障碍对于任何需要快速收集精确全球信息的人而言都是一个难题,甚至包括情报机构,美国情报机构IARPA项目主管卡尔·鲁比诺说:“一个人对了解世界越感兴趣,他就越有能力获得非英语的资源数据,现今我们面临诸多挑战,例如:经济、政治不稳定,新冠病毒肆意传播,全球气候变化,探索地外空间等,这些挑战都将面临着多语言环境。”
培训一名人工译员或者情报分析员学习一门新语言可能需要几年时间,即便如此,它可能也不足以完成当前的任务。鲁比诺说:“例如:在尼日利亚,人们使用的语言超过500种,即使是尼日利亚国内最优秀的语言专家,也可能仅懂得其中部分语言。”
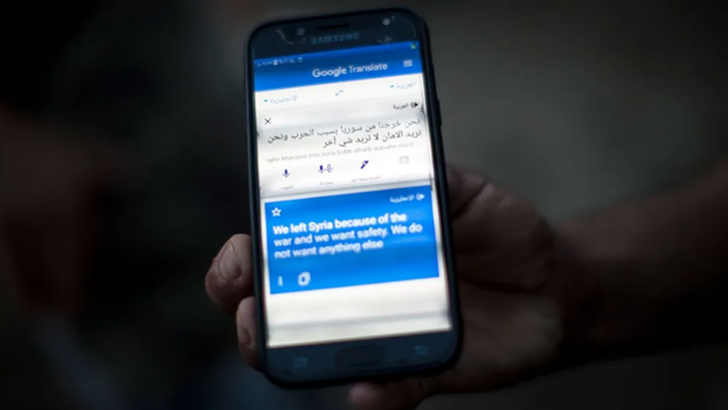
机器翻译工具可以在没有人工翻译的情况下提供重要的交流方式
为了突破这一障碍,IARPA投资一项研究,用于开发一种语言系统,能够从任何资源匮乏的语言(无论是文本语言还是语音语言)中寻找、翻译和总结信息。
人们可以想象一下,一种新型搜索软件,用户在搜索框键入英文,就会收到一个英文摘要文档列表,这些文档都是从某种外语翻译过来的,当他们点击其中一个文档,完整的翻译文件就会生成,虽然该研究经费来自于IARPA,但研究是由竞争团队公开进行,其中大部分翻译文件现已发布。
人们学习一门语言,并不是用于阅读几年以来的国际议会记录。
美国哥伦比亚大学计算机科学家凯瑟琳·麦基翁带领一支研究团队,致力于研究多语种翻译,她发现该领域带来的益处远超出情报侦察,她说:“我们的最终目标是促进来自不同文化的人们产生更多互动交流,以及获得更多关于他们的信息。”
该研究团队使用神经网络技术来解决这一难题,这是一种模仿人类思维某些方面的人工智能形式,近年来,神经网络模式已经彻底改变了语言处理,他们可以学习单词和句子的含义,而不仅仅是记忆单词和句子,他们结合上下文发现,像英语中的“dog”、“poodle”,与法语中的“chien”表达的概念是相似的,即使它们字母构成相差很大。
然而,要做到这一点,该语言模型通常需要经过数百万页文字翻译训练,其挑战在于让语言模型像人类一样,基于少量数据学习,毕竟人类不需要阅读几年的国际议会记录来学习一门语言。
美国麻省理工学院计算机科学家蕾贾纳·巴尔齐莱是另一支研究团队的成员,她说:“无论你何时学习一种偏门语言,相信你一生之中都不会看到现今机器翻译系统用于学习英法互译的数据量,你能看到非常少量的一部分语言翻译数据,能概括和理解法语。同样地,你也希望看到新一代机器翻译系统,即使没有迫切需要语言翻译数据的需求。”
为了解决这个难题,每个研究团队被分为更小的专家小组,他们致力于完善语言翻译系统,该系统的主要组成部分是:自动搜索、语音识别、翻译和文本概括技术,以上均适用于资源较少的语言。自2017年该项目开始以来,研究团队已经研究了8种不同语言,包括:斯瓦希里语、塔加拉语、索马里语和哈萨克语。
其中一个突破是从网络上获取文本和语音,包括新闻文章、博客和视频内容,由于世界各地网络用户都在使用自己的母语发布信息,许多资源匮乏的语言在线数据也在不断增多。
南加州大学计算机科学家斯科特·米勒说:“如果你搜索互联网,想获取索马里语的相关数据,你会找到上亿个单词,这是没有问题的,你可以在网络上获得几乎所有语言的文本资料。”
以上在线数据通常是单一语言模式,意味着索马里语文章或者视频只能使用母语阅读,没有平行对应的英语翻译。但是米勒表示,神经网络模型可以在许多不同语言的单语数据上进行预训练。
米勒称,在预训练过程中,神经模型学习了人类语言的一般结构和特征,然后可以将这些结构和特征应用到翻译任务中,没有人真正知道这些模型真正学到了什么结构,它们有数百万个参数。

打破语言障碍带来的好处远远超出了情报机构掌握到的信息
一旦对多种语言进行预训练,这些神经模型就可以使用极少的双语训练(即并列数据)在不同语言之间进行翻译,几十万字的并行数据就足够了——相当于几本小说的内容。
在这个总结概括过程中,神经模型表现出一些最奇特的方式——它们能产生“幻觉”。
多语言搜索引擎能够梳理文本形式的语言,这将带来另一组复杂的问题,例如:语音识别和转录技术通常会遇到之前未遇到过的声音、名称和位置问题。
英国爱丁堡大学语音技术专家彼特·贝尔是试图解决该问题的小组成员之一,他说:“我举的一个例子中所涉及的国家与西方国家相比不太出名,该国一个政客被暗杀,他的名字现在真的很重要,但在以前,这个名字很晦涩,并不引人关注,那么你如何在音频中找到这位政客的名字呢?”
贝尔和同事采取的一种解决方案是再次检索那些被转录的带有不确定性的单词,翻译软件并不熟悉这些不确定性的单词,如果再次重新检索,很可能就会找到这位鲜为人知的政客的名字。
一旦找到并翻译了相关信息,搜索引擎就会为用户进行汇总,在这个总结的过程中,神经模型会表现出一些最奇怪的特征——产生“幻觉”。
想象一下,当你正在搜索一篇关于星期一抗议者攻击某栋建筑的新闻报道,但搜索结果显示,抗议者的暴力行径是发生在星期四,这是因为神经模型在总结报告时,利用了基于数百万页训练文本的背景知识。在这些文本中,有更多的抗议者在星期四攻击建筑物,因此得出结论。
类似地,语言翻译软件的神经模型可能在摘要概述中插入日期或者数字,计算机科学家称之为“幻觉”。
爱丁堡大学计算机科学家米蕾拉·拉帕塔称,这些神经网络模型非常强大,它们记忆了很多语言,还添加了源程序中没有的单词。据悉,她正在为一支研究团队开发设计语言概述元素。
米蕾拉和同事通常提取每个文档中的关键词来避免该问题,而不是让翻译软件使用句子进行总结,关键词不如句子优雅,但它们限制了该语言模型表达韵文诗歌的倾向。
当新冠病毒大流行时,人们突然要将一些基本的健康提示翻译成多种语言。
虽然语言搜索引擎是为现有语言而设计的,但是该项目包括了一个研究数千年、现无人使用的小语种,这些古老的语言资源非常少,因为许多语言仅以文本片段的形式存在,他们为可应用于现代低资源语言的技术提供了一个有效试验。
麻省理工学院博士生Jiaming Luo和合作者共同开发了一种语言算法,可以计算出某些古代语言是否有现代存留,通过提供这些语言的基本信息,以及语言变化的通常状况,该语言算法获得了一个先行条件,基于以上信息,该语言模型能够独自获得一些发现,期间仅使用少量数据。

机器学习可以帮助破译已经灭绝的语言,比如公元前14至12世纪在叙利亚北部使用的乌加里特语
通过这种语言算法,他们发现一种来自近东地区的古老语言乌加里特语与希伯来语密切相关,他们还得出结论称,一种古老的欧洲语言——伊比利亚语,与其他欧洲语言相比,更接近于巴斯克语(但与巴斯克语的关联度并不高)。
麻省理工学院计算机科学家蕾贾纳希望该方法能够激发更广泛的变化,并使神经模型不那么需要数据支持,事实证明,我们对大量并行语言翻译数据的依赖,已成为研发语言翻译系统的一个弱点,因此,如果我们真的研制好的技术,无论是用于解密,还是用于小型语言翻译,它都将推动整个领域向前发展。
研究小组现已成功设计了多语言搜索引擎的基础版本,并用每种新语言对其进行改进,IARPA项目经理鲁比诺认为,这些技术可以改变情报收集的方式,我们确实有机会彻底改变分析师对外语数据的学习方法,使讲英语的单语分析师获得之前无法处理的多语数据。
当情报分析人员试图从外部获取资源稀缺的语言数据时,该语言的母语者们也在积极获得其他语言的重要信息,他们不是为了间谍活动,而是为了改善自己的日常生活。
德国萨尔兰大学计算机科学博士生戴维·伊费奥鲁瓦·阿德拉尼说:“当新冠病毒全球流行时,突然需要将基本的卫生提示翻译成多种语言,由于翻译质量问题,我们无法使用机器翻译模型实现这一点,我认为开发多语言翻译软件教会我们很多东西,拥有适合于资源匮乏语言的技术是非常重要的,尤其是在我们急需的时候。”
阿德拉尼来自尼日利亚,他的母语是约鲁巴语,他一直在创建约鲁巴语-英语互译的数据库,这是名为“打破非洲多语言障碍”的非赢利项目的一部分,他和研究团队通过收集翻译后的电影剧本、新闻、文学作品和公开演讲等资料,创建了一个新的数据集。然后,他们利用这个数据集对宗教文本模型进行微调,以提高该数据集的准确性。在Masakhane等基层团体的帮助下,埃维语、契维语、卢干达语等其他非洲语言也在进行类似的努力。
相信未来有一天,我们所有人都可能在日常生活中使用多语言搜索引擎,只需点击一个按钮,就能解锁世界知识,在此之前,真正理解一种资源匮乏语言的最好方法可能就是学习它,并加入多语言在线人类交流。(叶倾城)
 公安机关备案号: 13020002152308
公安机关备案号: 13020002152308


